Research
Resources Rot : des centaines de millions de sites web à risque
Resources Rot: Hundreds of Millions of Websites at Risk

Que se passerait-il si le domaine www[.]google-analytics[.]com présent sur des milliards de sites venait à expirer et à ne pas être renouvelés ? Les sites non mis à jour serviraient alors du code obsolète qui tenteraient en vain de charger et d'exécuter des scripts. Un tiers pourrait s'emparer du domaine expiré et diffuser du code malveillant sous ce domaine. On parle alors en sécurité offensive de détournement de lien (Broken Link Hijacking).
Dans le cas le plus favorable, un lien cassé entraîne simplement une mauvaise expérience pour l'utilisateur ou voir se révèle inutile. Mais dans le cas le plus défavorable, il va constituer une menace pour la cybersécurité de toute personne visitant le site web.
Selon la façon dont le lien est utilisé dans le code du site web, il existe plusieurs façons d'exploiter la vulnérabilité, avec des niveaux de risque variables.
Un peu de contexte
La problématique des liens brisés (ou lien mort) est un phénomène du web observé depuis les années 1990. A cette époque, 3% de tous les liens hypertextes devenaient brisés après un an (Nelson et Allen, 2002). En moyenne, tout lien URL confondu, la durée de vie moyenne est de deux ans (Hans van der Graaf, 2017).
La problématique a surtout été couverte dans le domaine de la recherche académique. En effet, une publication scientifique qui cite ses sources au travers de liens hypertextes pourrait poser des problèmes de crédibilité, de vérification par les pairs et de reproductibilité des résultats.
En revanche, le statut des liens hypertextes (code d'erreur des ressources externes appelées par un site web pour rendre un service à l'utilisateur) est moins voire pas étudié. Cela peut concerner le stockage d'une image, d'une vidéo, d'un code javascript ou d'une feuille de style (CSS) par exemple. Suivant la nature de l'indisponibilité de la ressource, des questions de sécurité informatique se posent, notamment par la militarisation de ces anomalies à des fins malveillantes.
Les liens brisés vers des ressources
Les liens hypertextes sont par définition la base même du web. Ils relient les ressources web entre elles et permettent aux visiteurs de naviguer entre les pages, d'avoir un contenu dynamique et un rendu ergonomique.
Voici un exemple de liens pouvant exister sur un site correctement configuré :
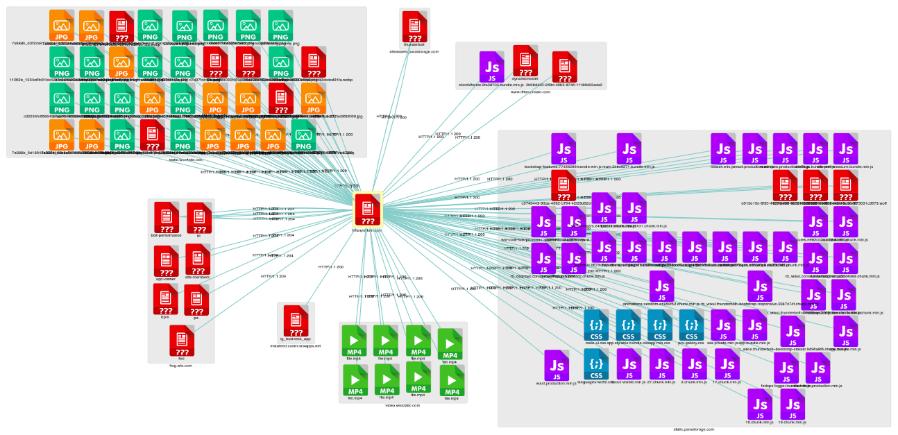
Voici ce que cela donne sur un site comportant un nombre important de liens brisés :
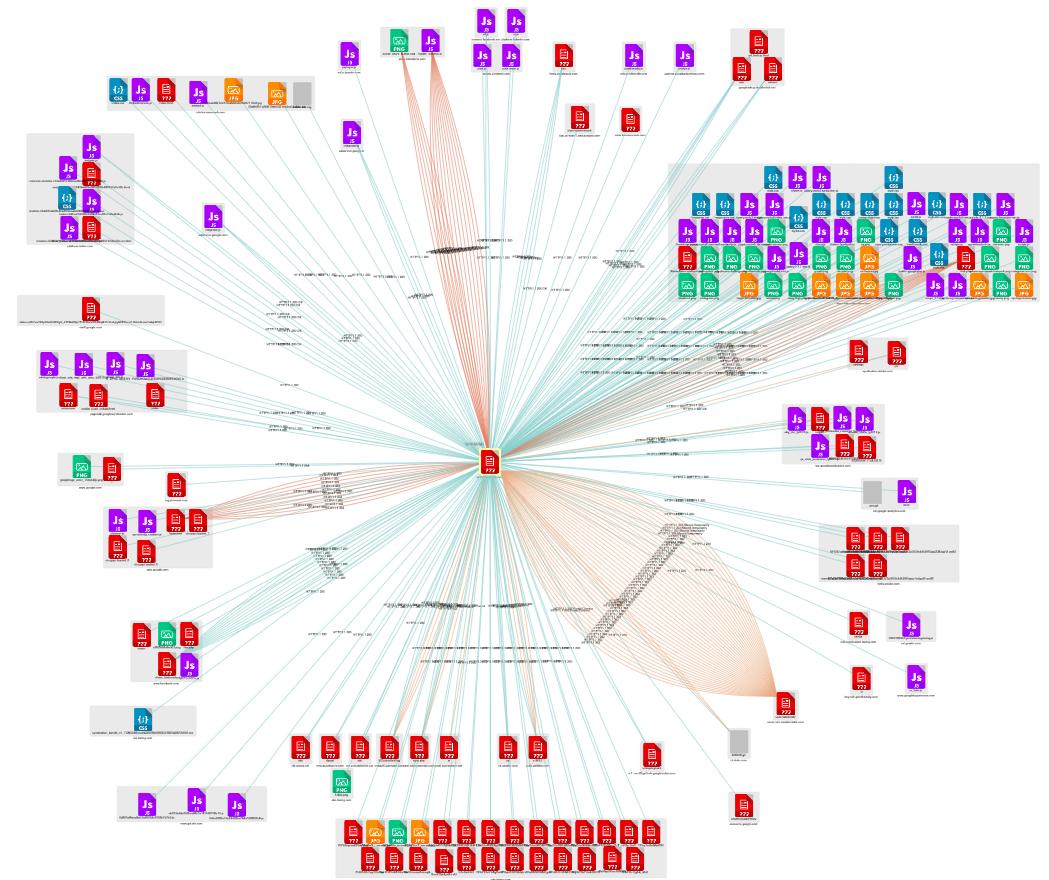
Toutefois, bien que valide lors de la création du site web, ces ressources évoluent au cours du temps et peuvent disparaître : des bibliothèques ne sont plus maintenues, les domaines sont volés ou non renouvelés, des serveurs sont fermés. Le web est dynamique et les ressources qui sont disponibles aujourd'hui ne le seront peut être pas demain.
Mais certains liens brisés peuvent l'être dès la mise en ligne d'un site internet, à cause d'erreurs de programmation ou de coquilles dans les adresses invoquées.
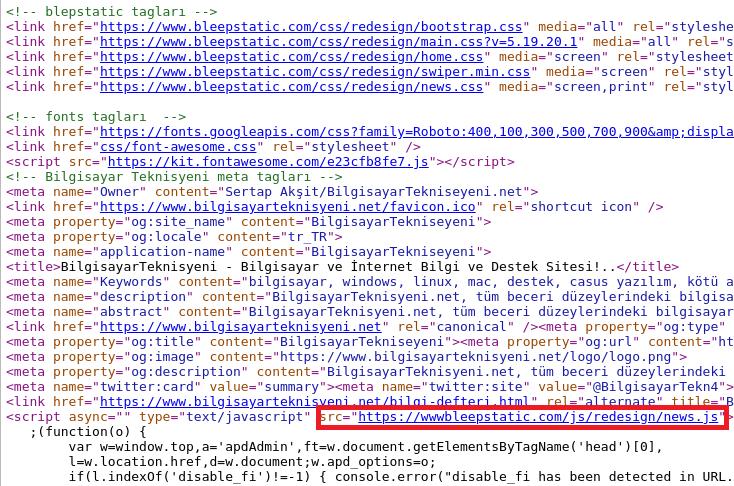
Ci-dessous un lien cassé provenant d'une erreur du programmeur ayant oublié un point pour le chargement de ce script qui est donc chargé sur wwwbleepstatic[.]com au lieu de www[.]bleepstatic[.]com.
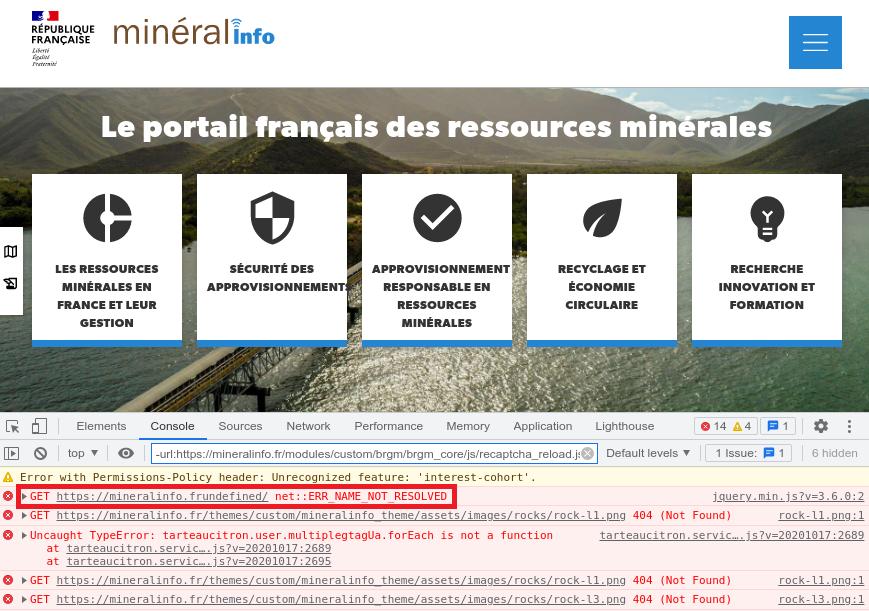
Dans le site ci-dessous un slash a été oublié entre le domaine en « .fr » et la ressource à charger, le navigateur essaye donc de résoudre un domaine avec une extension en « .frundefined ».
Broken links hijacking
Dans le cas le plus favorable, un lien cassé entraîne simplement une mauvaise expérience pour l'utilisateur ou voir se révèle inutile. Mais dans le cas le plus défavorable, il va constituer une menace pour la cybersécurité de toute personne visitant le site web.
Les attaques typiques par détournement de liens sont les suivants :
- Library Hijacking : Des liens vers des bibliothèques supprimées et remplacées par une autre homonyme
- Domain Hijacking : Des liens vers des domaines expirés qui peuvent être enregistrés ou achetés.
- Subdomain Hijacking : Des liens vers des sous-domaines qui ne sont plus utilisés et qui sont vulnérables à une prise de contrôle.
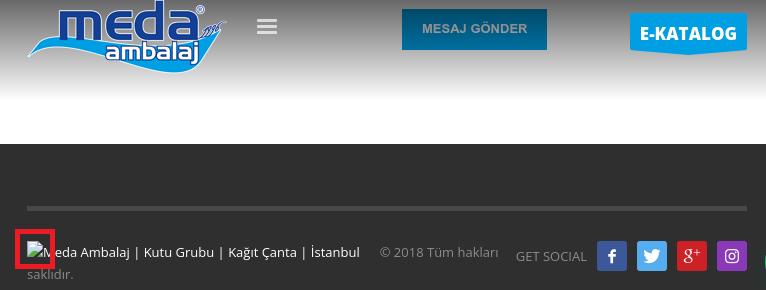
Ci après un exemple de lien cassé dans un footer de page résultant en un chargement d'une image impossible par le navigateur, ce dernier le signale en affichant une image cassée :
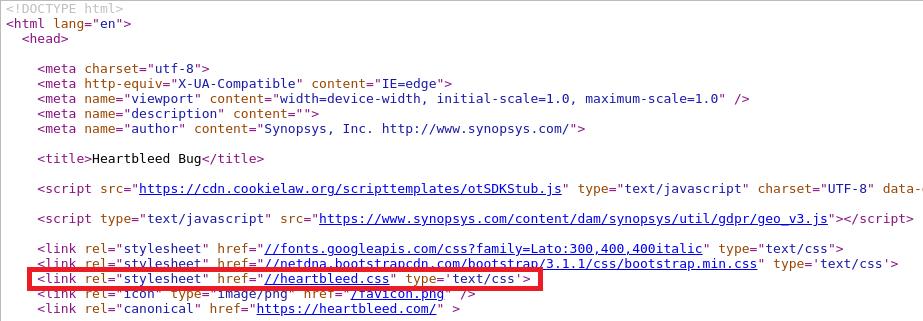
Même dans le domaine de la sécurité certains sites sont touchés, comme celui de la tristement célèbre faille OpenSSL Heartbleed qui essaie de charger une feuille de style CSS sur « heartbleed.css » qui bien sur n'est pas un site valide.
Si un acteur malveillant arrive à prendre la main sur des ressources externes appelées, il pourrait y injecter des scripts exécutés par le navigateur de la victime et porter préjudice aux sites qui l'utilisent. Un lien brisé d'image ou de CSS pourrait être utilisé pour défigurer un site web (Defacement). Plus grave un lien brisé permettant d'exécuter du code ouvrirait la porte à du vol de données, à la prise de contrôle du serveur ou au piratage de ses visiteurs.
Abandon de noms de domaine à fort trafic
Un cas particulier de causes de liens brisés est le non renouvellement d'un nom de domaine par son propriétaire. Tel le bail d'une location, chaque nom de domaine est attribué à son propriétaire pour une période donnée. En cas de non paiement ou renouvellement du bail, le nom de domaine est de nouveau accessible à l'achat. Ce non renouvellement peut être un oubli, ou bien un abandon pur et simple suite à une Fusion-Acquisition par exemple.
Un des premiers cas célèbre est le non renouvellement du domaine appartenant à Microsoft, passport[.]com, fin 1999. Ce domaine servait à l'authentification sur la messagerie Hotmail. Le nom de domaine a été renouvelé par un utilisateur vigilant, remboursé peu après par Microsoft. La même histoire se répète en octobre 2003 avec le domaine hotmail[.]co[.]uk.
D'autres organisations, des plus modestes à des géants de la Tech comme FourSquare en 2010 ou Google Argentine en avril 2021 ont échoué à gérer proprement leur renouvellement de nom de domaine, sans effet néfaste bien heureusement.
En 2020, des chercheurs de l'Unit42 de la société de sécurité Palo Alto ont découvert que des domaines « parking » (achetés pour être simplement mis en vente) précédemment expirés étaient utilisés pour propager le logiciel malveillant Emotet. Selon leur analyse, 1% des domaines en parking étaient utilisés à des fins malveillantes, soit un potentiel de 3000 domaines par jour.
En 2021, les chercheurs de la société de sécurité Sucuri ont mis au jour une attaque exploitant le domaine non renouvelé tidioelements[.]com du défunt plugin WordPress « visual-website-editor ». Des pirates ont enregistré ce nom de domaine pour y injecter du code malveillant javascript.
La réutilisation à des fins malveillantes de domaines abandonnés peut également s'avérer un vecteur très efficace pour les phishing ou la fraude, utilisant la marque et la réputation de l'organisme originellement détenteur du nom de domaine.
Méthodologie
Notre hypothèse principale est que des sites à très fort trafic peuvent avoir des liens brisés. Nous pensons également que certains de ces liens sont brisés pour cause d'expiration de nom de domaine et donc sujet à des attaques par détournements de liens.
A des fins d'investigation, nous avons développé un crawler visant à scanner les sites de la même manière que le ferait un utilisateur visitant le site avec son navigateur.
Ce robot est spécifique à un scan de surface : il vient parcourir une liste de domaine issue des listes d'Alexa, inspecte les références externes appelées par le code HTML des pages d'accueil visitées et récupère les informations sur les liens brisés.
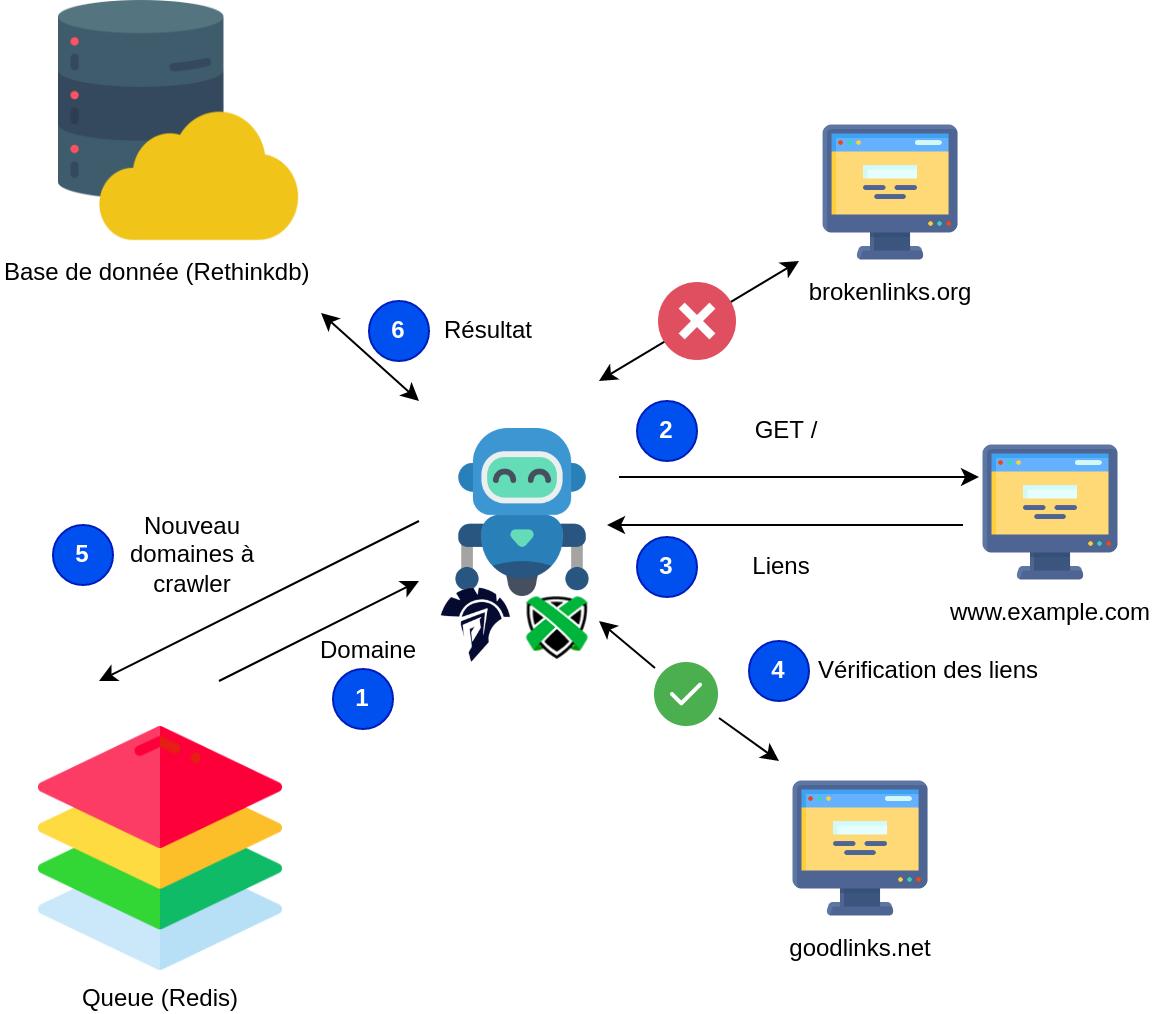
Le fonctionnement de l'analyse des pages HTML par le robot est le suivant : pour chaque page d'accueil visitée, le robot enregistre l'ensemble des dépendances, leur type (script, img, css…), leur taille ainsi que les codes HTTP de réponses (200, 302, 404…).
Si le domaine de la ressource n'existe pas et est un nom de domaine valide, le robot récupère alors l'enregistrement whois si il existe.
Le code du robot a dû être adapté à plusieurs reprises suite à la découverte de nouveaux cas de blocage comme les limitations sur le nombre de requêtes whois, les sites qui chargent des dépendances en continue ou des sites trop long à répondre.
Résultats
Nous avons analysé 88 000 pages d'accueil extraites depuis le Majestic et Alexa. Nous avons identifié un total de 6 325 915 liens vers des ressources externes, dont 30 960 sont brisés (0.5%).
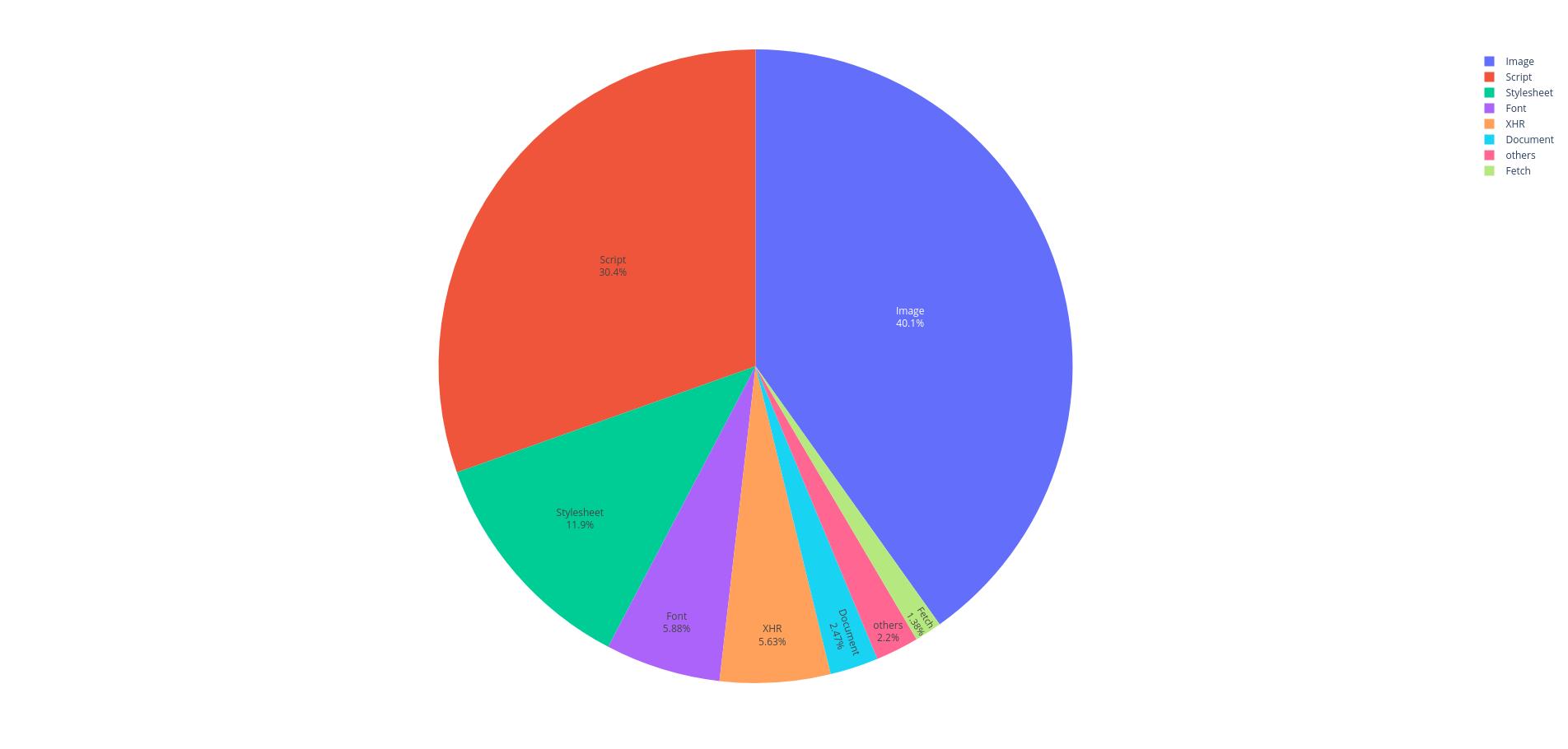
Les images ainsi que les codes javascript représentent un peu plus de 70% des ressources externes.
Sur les 88 000 pages d'accueil, 30 960 ont au moins un lien brisé (35,2%).
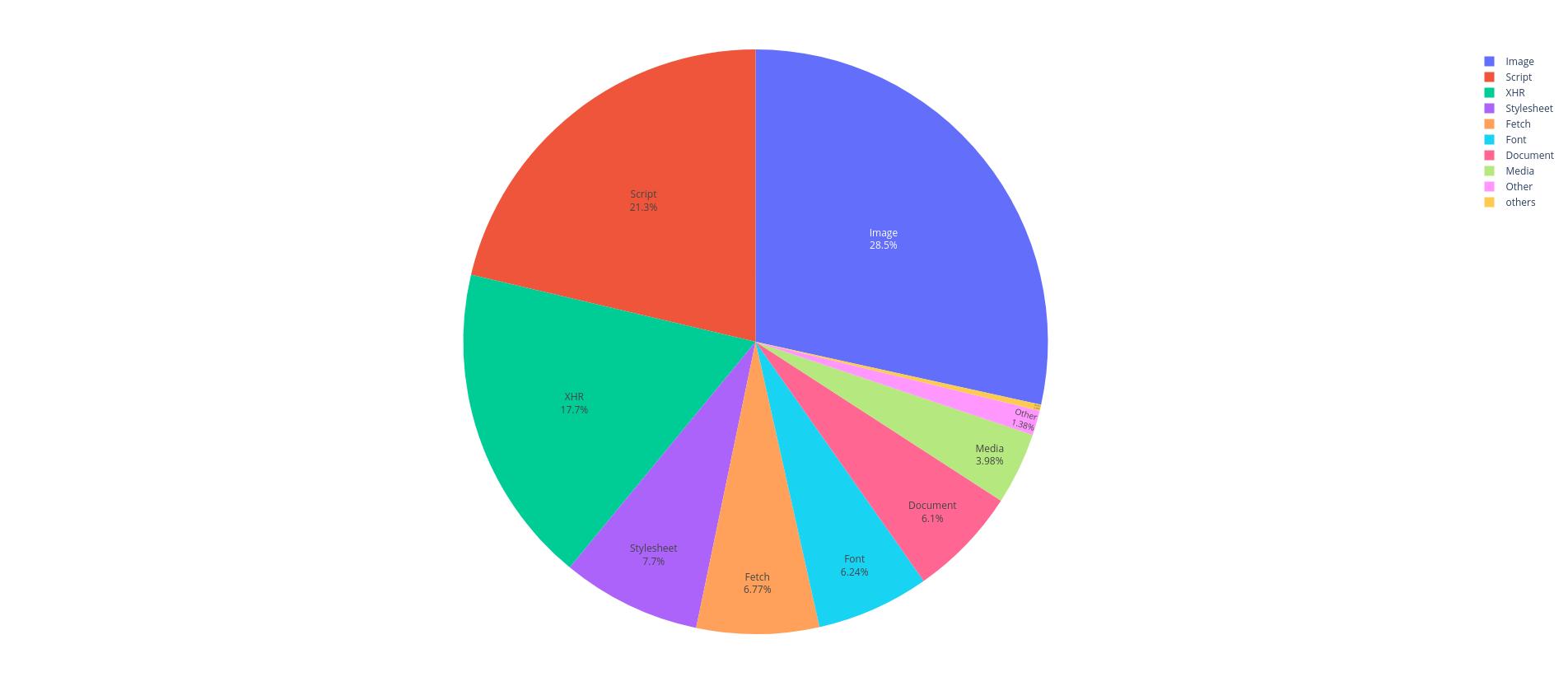
Les images ainsi que les objets XMLHttpRequest, et les codes javascript représentent un peu plus de 70% des ressources externes invalides.
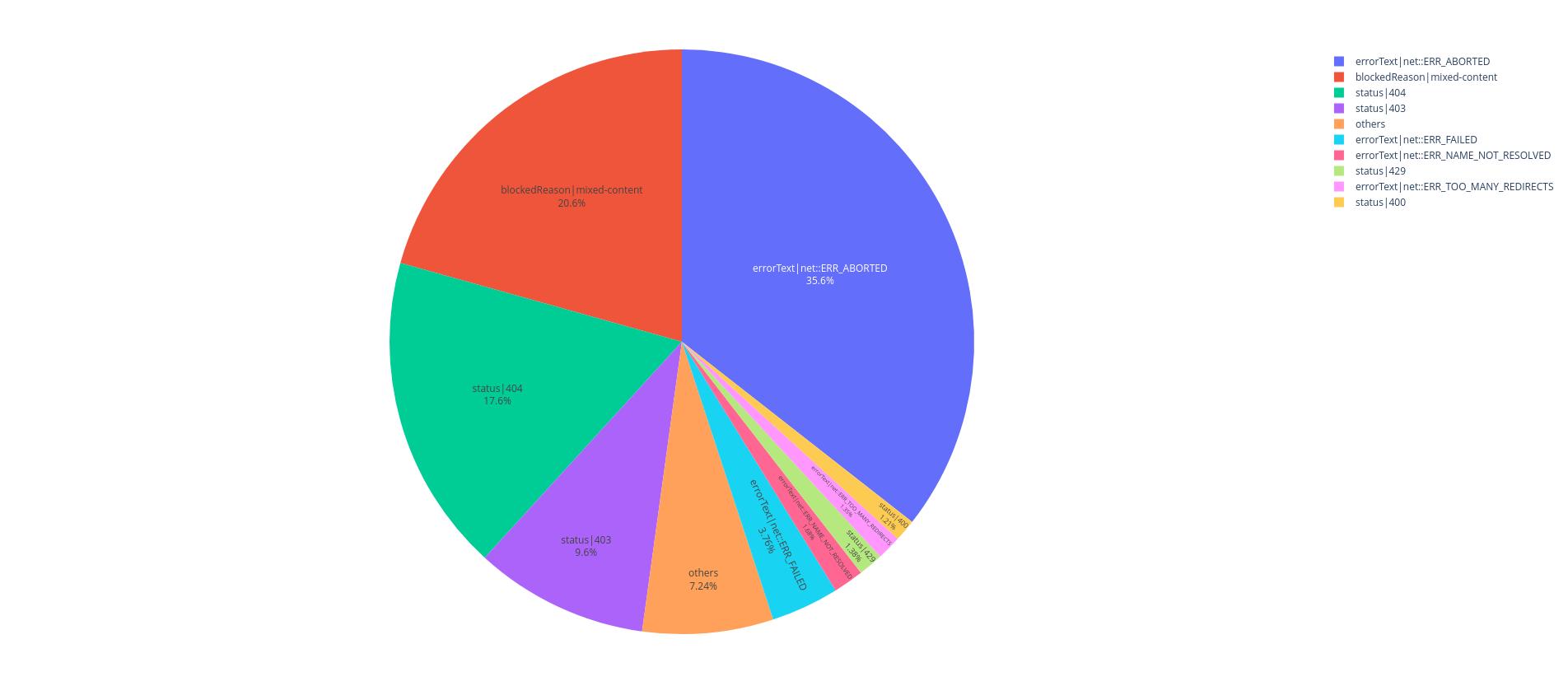
Les causes d'erreurs les plus fréquentes sont les mixed-content, les ressources non trouvées (HTTP 404 et javascript net::ERR_ABORTED) et les ressources sous restrictions d'accès (HTTP 403) représente près de 70% des erreurs :
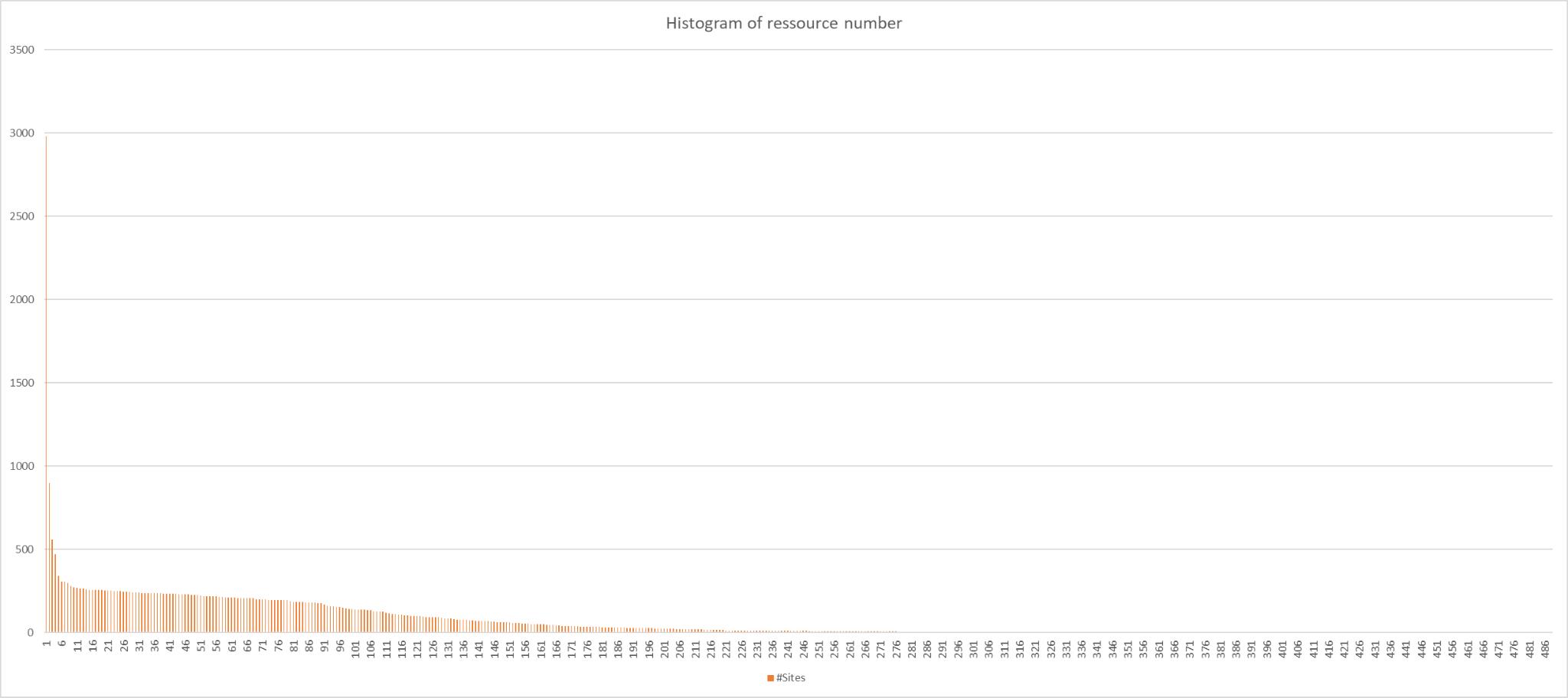
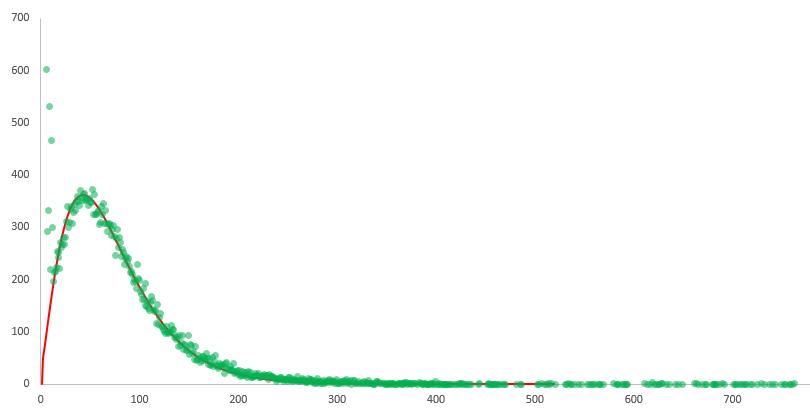
En moyenne, nous avons déterminé que la page d'accueil d'un site a 72 dépendances. 60% sont internes et 40% externes.
La distribution ainsi principalement observée est une loi gamma. Ce point est intéressant et permet de modéliser partiellement la répartition du nombre de dépendances par site. On remarque aussi que le début de la distribution ne correspond pas à une loi gamma : notre hypothèse est que cette distribution serait la somme d'au moins deux distributions différentes. De par le faible nombre de points, il ne nous est pas possible de la déterminer. On constate qu'elle est simplement strictement monotone et décroissante.
Un autre résultat intéressant est le TOP 10 des domaines référencés :
| Domain | Number |
|---|---|
| https://facebook.com | 42 731 |
| https://twitter.com | 36 992 |
| https://instagram.com | 28 528 |
| https://youtube.com | 24 369 |
| https://linkedin.com | 16 401 |
| https://google.com | 9 165 |
| https://pinterest.com | 6 273 |
| https://wordpress.org | 3 373 |
| https://apple.com | 3 300 |
| https://vk.com | 1 398 |
Interprétation
Au regard de notre analyse, on constate que 0.8% des pages d'accueil ont au moins un lien brisé, quel que soit le type d'erreur. Si ce pourcentage semble faible, il faut le ramener à l'ordre de grandeur du web. Selon le World Economic Forum, en 2021, il y aurait 1,88 milliards de sites web. Ainsi, près de 662 millions de sites web pourraient être affectés par des liens de ressources morts et présenter un risque.
En prenant quelques échantillons, pour une approche qualitative, nous avons remarqué que les erreurs de programmation sont souvent à l'origine de ces liens cassés (impossible à évaluer automatiquement) : les points mal placés, des lettres inversées, des séparateurs « / » oubliés entre le domaine et la ressource, ou encore la ressource prise pour le domaine (exemple : chargement de https://ressource[.]js au lieu de https://<domain>/ressource.js). Cela signifie que ces anomalies sont présentes avant la mise en production et cela traduit une implémentation lacunaire voire inexistante des phases de tests.
Une autre catégorie d'anomalie très présente concerne les noms de domaines non renouvelés par des régies publicitaires ou des agences de webdesign (impossible à dire automatiquement). Cela pourrait s'expliquer par un mauvais suivi des dates d'expiration des domaines ou par la cessation des activités de l'entreprise.
Si certains sites ne nécessitent que peu de ressources, d'autres peuvent en avoir plusieurs centaines. Notamment, les régies publicitaires jouent pour beaucoup dans ce nombre de requêtes.
La valeur moyenne de ressource par page web est une métrique intéressante à observer, car chaque ressource est un vecteur de risque supplémentaire pour le site. Certaines de ces ressources externes peuvent être critiques pour le bon fonctionnement du site. Si certaines anomalies peuvent être très visibles rapidement, d'autres touchant des ressources de tâches de fond sont plus difficiles à détecter.
Limitations
La non exhaustivité de nos listes de domaines implique nécessairement l'introduction d'un biais d'échantillonnage. En effet, les sites analysés relèvent nécessairement d'un domaine intéressant les masses grands publics (e.g e-commerce, blog, etc.), mais c'est le choix assumé de cette étude de se concentrer sur l'impact maximal possible en cas d'usage malveillant. En revanche, ces sites à très fort trafic peuvent reposer plus que les autres sur des CMS. Ainsi notre analyse pourrait ne pas être celle des sites à fort trafic, mais celle des technologies et méthodologies sous-jacentes utilisées pour les développeurs.
Il est aussi primordial de tenir compte de l'aspect temporel du web et de sa volatilité : ce qui est vrai aujourd'hui ne peut plus l'être demain. Si nous venions à l'avenir à refaire la même expérience avec la même infrastructure et le même protocole, nous trouverions peut-être des résultats statistiques différents.
Opportunités de recherches
Pour aller plus loin dans notre exploration du web nous pourrions scanner ces mêmes sites à fort trafic (ex : Majestic Million) en profondeur pour en analyser le pourcentage de liens cassés sur l'ensemble du site, et non plus uniquement sa page d'accueil.
Nous pourrions également reproduire le test tous les six mois ou tous les ans, afin d'analyser les tendances sur les références externes et leurs anomalies associées.
Dans l'immédiat, notre prochaine recherche s'intéresse à un cas particulier : les domaines expirés achetables présents dans les liens brisés. Étant disponible à l'achat, il est ainsi possible de les récupérer et d'analyser l'ensemble du trafic hérité de l'ancien service.
Il devrait ainsi être possible de faire des statistiques sur ce trafic (bot, user agent, OS, etc) de manière complètement passive.
Conclusion
En conclusion nous avons pu voir que des liens cassés sont omniprésents sur le web et notamment concernant les ressources externes. Si des recherches existent sur le phénomène des liens morts dans les textes et architecture de site web, ainsi que sur l'usage de librairies externes vulnérables, nous n'avons pas trouvé de références académiques sur notre sujet particulier des liens morts dans les références de ressources externes.
Nos recherches préliminaires indiquent que potentiellement des centaines de millions de sites sont touchés par ce problème. Ils peuvent présenter un risque pour le visiteur de se voir distribuer du contenu malveillant et un risque pour l'entreprise hébergeant le site d'atteinte à son image.
Nous allons poursuivre nos recherches, en achetant des noms de domaines expirés et en analysant le trafic afin de mieux comprendre quelles populations pourraient être visées dans le cas d'une opérationnalisation malveillante de cette anomalie endémique du web.
A propos des auteurs
Nicolas et Laurent sont deux passionnés de DIY et de cybersécurité, ayant décidé de créer chacun leur entreprise de sécurité numérique : X-Rator et Spartan conseil, respectivement.
Ayant chacun des compétences complémentaires, ils ont décidé de se mettre à quatre mains et d'écrire une série d'articles sur la cybersécurité, pour le plus grand plaisir des lecteurs.
Un grand merci à Ronan pour son aide et son expérience rédactionnelle.
What would happen if the domain www[.]google-analytics[.]com, present on billions of websites, were to expire and go unrenewed? Outdated sites would continue serving stale code that futilely attempts to load and execute scripts. A third party could register the expired domain and distribute malicious code under it. In offensive security, this technique is known as Broken Link Hijacking.
In the best-case scenario, a broken link simply results in a degraded user experience or serves no purpose. In the worst case, it poses a cybersecurity threat to every visitor of the affected website.
Depending on how the link is used in the site's code, there are multiple ways to exploit the vulnerability, with varying levels of risk.
Background
The broken link problem (also known as link rot) is a web phenomenon that has been observed since the 1990s. At that time, 3% of all hyperlinks became broken within a year (Nelson and Allen, 2002). On average, regardless of link type, the mean lifespan of a URL is two years (Hans van der Graaf, 2017).
The issue has been primarily addressed in academic research. A scientific publication citing sources through hyperlinks risks credibility issues, peer-review problems, and challenges in reproducing results when those links decay.
However, the status of hyperlinks pointing to external resources — the HTTP response codes of assets loaded by a website to deliver functionality to the user — has received little to no attention. These assets may include images, videos, JavaScript files, or CSS stylesheets. Depending on the nature of the resource's unavailability, serious information security concerns arise, particularly when such anomalies are weaponised for malicious purposes.
Broken Links to External Resources
Hyperlinks are, by definition, the fundamental building blocks of the web. They interconnect web resources and allow visitors to navigate between pages, access dynamic content, and experience consistent rendering.
Here is an example of links that can exist on a correctly configured site:
Here is what this looks like on a site with a significant number of broken links:
However, although valid when the website was created, these resources evolve over time and may disappear: libraries are no longer maintained, domains are stolen or not renewed, servers are shut down. The web is dynamic, and resources available today may not be tomorrow.
But some links can be broken from the moment a website goes live, due to programming errors or typos in the referenced addresses.
Below is a broken link caused by a developer forgetting a dot when loading a script, which is therefore loaded from wwwbleepstatic[.]com instead of www[.]bleepstatic[.]com.
In the site below, a slash was omitted between the « .fr » domain and the resource to load, so the browser attempts to resolve a domain with a « .frundefined » extension.
Broken Link Hijacking
In the best-case scenario, a broken link simply results in a degraded user experience or serves no purpose. In the worst case, it poses a cybersecurity threat to every visitor of the affected website.
Typical broken link hijacking attacks include:
- Library Hijacking: Links to deleted libraries replaced by a namesake.
- Domain Hijacking: Links to expired domains that can be registered or purchased.
- Subdomain Hijacking: Links to unused subdomains that are vulnerable to takeover.
Below is an example of a broken link in a page footer, resulting in a failed image load that the browser flags with a broken image indicator:
Even security-focused sites are affected, such as the infamous OpenSSL Heartbleed vulnerability page, which attempts to load a CSS stylesheet from « heartbleed.css » — obviously not a valid domain.
If a malicious actor gains control of referenced external resources, they could inject scripts executed by the victim's browser and cause harm to any site using them. A broken image or CSS link could be used to deface a website. More seriously, a broken link enabling code execution would open the door to data theft, server takeover, or hijacking of its visitors.
Abandonment of High-Traffic Domain Names
A particular cause of broken links is the failure of a domain owner to renew their domain name. Like a rental lease, each domain name is assigned to its owner for a given period. If the lease is not paid or renewed, the domain name becomes available for purchase again. This non-renewal may be an oversight, or a deliberate abandonment following a merger or acquisition, for example.
One of the first famous cases was Microsoft's failure to renew passport[.]com at the end of 1999. This domain was used for authentication on the Hotmail email service. The domain was renewed by a vigilant user, who was later reimbursed by Microsoft. The same story repeated itself in October 2003 with the domain hotmail[.]co[.]uk.
Other organisations — from small businesses to tech giants like FourSquare in 2010 or Google Argentina in April 2021 — have failed to properly manage their domain renewals, fortunately without harmful consequences.
In 2020, researchers from Palo Alto's Unit42 discovered that previously expired "parked" domains (purchased simply to be listed for sale) were being used to spread the Emotet malware. According to their analysis, 1% of parked domains were used for malicious purposes, representing a potential of 3,000 domains per day.
In 2021, researchers at security firm Sucuri uncovered an attack exploiting the unrenewed domain tidioelements[.]com from the defunct WordPress plugin "visual-website-editor". Attackers registered this domain name to inject malicious JavaScript code.
The malicious reuse of abandoned domains can also prove to be a highly effective vector for phishing or fraud, leveraging the brand and reputation of the organisation that originally held the domain.
Methodology
Our main hypothesis is that very high-traffic websites can have broken links. We also believe that some of these broken links are caused by expired domain names and are therefore subject to link hijacking attacks.
For investigative purposes, we developed a crawler designed to scan sites in the same way a user would visit them with a browser.
This crawler is specifically designed for surface scanning: it iterates through a list of domains from the Alexa rankings, inspects external references called by the HTML code of visited homepages, and retrieves information about broken links.
The crawler's HTML page analysis works as follows: for each visited homepage, the crawler records all dependencies, their type (script, img, css…), their size, and HTTP response codes (200, 302, 404…).
If the resource's domain does not exist and is a valid domain name, the crawler then retrieves the whois record if available.
The crawler code had to be adapted several times following the discovery of new blocking scenarios, such as rate limits on whois queries, sites that continuously load dependencies, or sites that take too long to respond.
Results
We analysed 88,000 homepages extracted from Majestic and Alexa. We identified a total of 6,325,915 links to external resources, of which 30,960 are broken (0.5%).
Images and JavaScript code account for just over 70% of external resources.
Out of the 88,000 homepages, 30,960 have at least one broken link (35.2%).
Images, XMLHttpRequest objects, and JavaScript code account for just over 70% of invalid external resources.
The most common error causes are mixed-content issues, resources not found (HTTP 404 and JavaScript net::ERR_ABORTED), and access-restricted resources (HTTP 403), accounting for nearly 70% of errors:
On average, we determined that a website's homepage has 72 dependencies. 60% are internal and 40% are external.
The distribution primarily observed follows a gamma distribution. This is interesting as it allows partial modelling of the distribution of the number of dependencies per site. We also note that the beginning of the distribution does not follow a gamma distribution: our hypothesis is that this distribution is the sum of at least two different distributions. Due to the small number of data points, we were unable to determine it. We observe that it is simply strictly monotone and decreasing.
Another interesting result is the TOP 10 most referenced domains:
| Domain | Number |
|---|---|
| https://facebook.com | 42,731 |
| https://twitter.com | 36,992 |
| https://instagram.com | 28,528 |
| https://youtube.com | 24,369 |
| https://linkedin.com | 16,401 |
| https://google.com | 9,165 |
| https://pinterest.com | 6,273 |
| https://wordpress.org | 3,373 |
| https://apple.com | 3,300 |
| https://vk.com | 1,398 |
Interpretation
Our analysis shows that 0.8% of homepages have at least one broken link, regardless of the error type. While this percentage seems low, it must be put in the context of the web's scale. According to the World Economic Forum, in 2021, there were 1.88 billion websites. Thus, nearly 662 million websites could be affected by dead resource links and present a risk.
Taking a few samples for a qualitative approach, we observed that programming errors are often the cause of these broken links (impossible to assess automatically): misplaced dots, inverted letters, forgotten « / » separators between the domain and the resource, or the resource being mistaken for the domain (e.g., loading https://ressource[.]js instead of https://<domain>/ressource.js). This means these anomalies are present before deployment and reflect a lacking or non-existent testing phase.
Another very common category of anomaly involves domain names not renewed by advertising networks or web design agencies (impossible to determine automatically). This could be explained by poor tracking of domain expiration dates or by the company ceasing operations.
While some sites require few resources, others may have several hundred. In particular, advertising networks account for a large share of these requests.
The average number of resources per webpage is an interesting metric to observe, as each resource represents an additional risk vector for the site. Some of these external resources may be critical to the site's proper functioning. While some anomalies may be quickly visible, others affecting background task resources are harder to detect.
Limitations
The non-exhaustiveness of our domain lists necessarily introduces a sampling bias. The sites analysed are necessarily of interest to the general public (e.g., e-commerce, blogs, etc.), but this study deliberately focuses on the maximum possible impact in case of malicious use. However, these high-traffic sites may rely more than others on CMSs. As a result, our analysis may reflect not the characteristics of high-traffic sites, but rather the underlying technologies and methodologies used by their developers.
It is also essential to account for the temporal nature of the web and its volatility: what is true today may not be true tomorrow. If we were to repeat the same experiment in the future with the same infrastructure and protocol, we might find different statistical results.
Research Opportunities
To go further in our exploration of the web, we could perform deep scans of the same high-traffic sites (e.g., Majestic Million) to analyse the percentage of broken links across the entire site, not just its homepage.
We could also repeat the test every six months or every year, to analyse trends in external references and their associated anomalies.
In the immediate term, our next research focuses on a specific case: purchasable expired domains found in broken links. Being available for purchase, it is possible to acquire them and analyse all the traffic inherited from the former service.
It should thus be possible to gather statistics on this traffic (bots, user agents, OS, etc.) in a completely passive manner.
Conclusion
In conclusion, we have seen that broken links are ubiquitous on the web, particularly regarding external resources. While research exists on the phenomenon of dead links in website text and architecture, as well as on the use of vulnerable external libraries, we found no academic references on our specific subject of dead links in external resource references.
Our preliminary research indicates that potentially hundreds of millions of sites are affected by this problem. They may pose a risk to visitors of receiving malicious content, and a reputational risk to the companies hosting those sites.
We will continue our research by purchasing expired domain names and analysing the traffic to better understand which populations could be targeted in the event of malicious operationalisation of this endemic web anomaly.
About the Authors
Nicolas and Laurent are two DIY and cybersecurity enthusiasts who each decided to start their own digital security company: X-Rator and Spartan Conseil, respectively.
With complementary skills, they decided to join forces and write a series of articles on cybersecurity, for the greatest pleasure of their readers.
Many thanks to Ronan for his help and editorial expertise.
Want to assess your exposure?
Our experts can audit the external dependencies of your web assets and help you eliminate silent security risks.